Recently, I started looking into testing and validating network configurations leveraging Batfish, Pandas and pytest. Doing something with Batfish has been on my to-do list for quite a while. After playing with it, I can say it is a real pity I did not start using this tool earlier.

This article aims to explain the basics of Batfish and how it can be leveraged during CI. After this, I will cover a bit of Pandas so you can work with the data that is produced by Batfish and I will finish up writing some unit tests using pytest. Code samples are available in a repo on Github, right here.
Batfish overview
The ‘why’ Batfish according to Batfish:
Batfish is a network validation tool that provides correctness guarantees for security, reliability, and compliance by analyzing the configuration of network devices. It builds complete models of network behavior from device configurations and finds violations of network policies (built-in, user-defined, and best-practices).
The idea is to analyze the configurations before deploying them. So your configuration files or changes are created, you can use Batfish as a tool to provide additional ‘correctness guarantees’. The areas in which Batfish can help are:
- configuration audits, verifying things are configured properly
- ACL and firewall analysis
- routing and forwarding analysis
- reachability analysis
Batfish components
There are two main components to Batfish:
- Batfish service: the software that analyzes the configurations
- Batfish client: the
pybatfishPython client that allows users to interact with the Batfish service.
The Batfish service can be run in a container and the Batfish client feeds the service with all the required input data:

The fact that Batfish does not require device access makes it particularly easy to integrate it into whatever automation tools already in place.
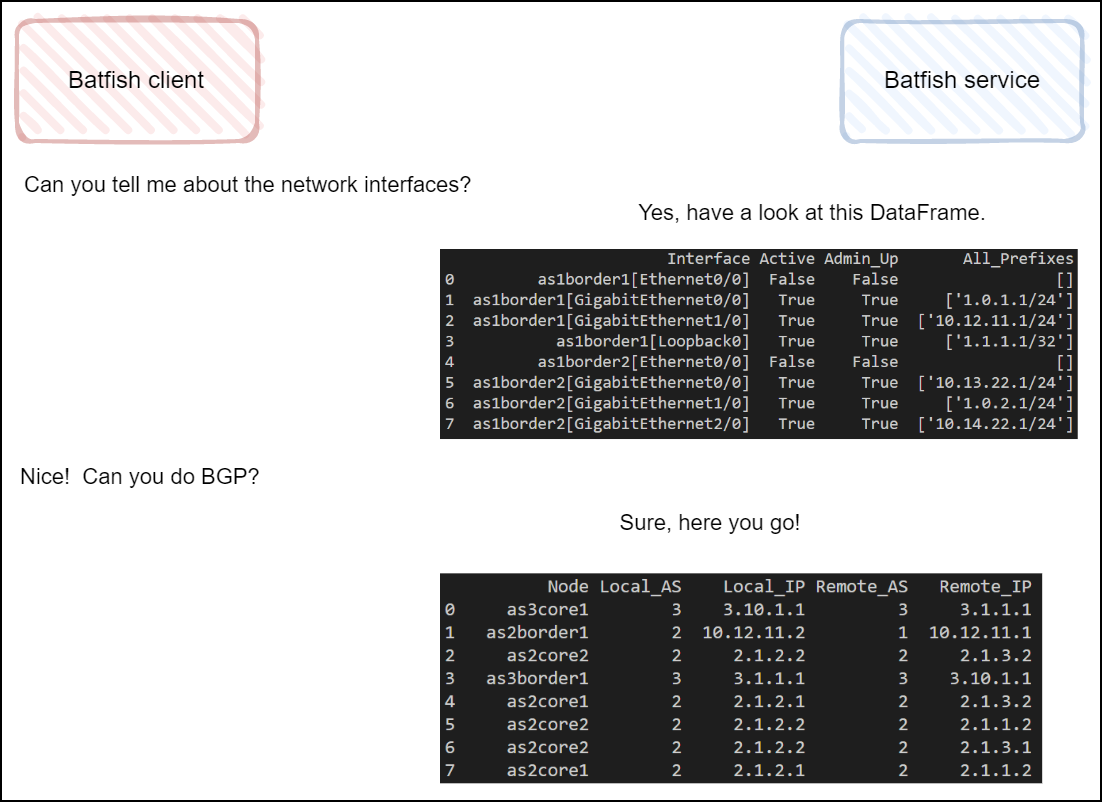
After receiving the configurations, the Batfish service will parse them. It then produces structured and vendor agnostic data models to represent the configurations. When the service is done generating the models, you can start using the client to ask the service ‘questions’. When the client is used to ask a question, the service will generate a repsonse in the form of a Pandas DataFrame:
These data models that the Batfish service builds for you are a real treasure trove. They can be put to good use for all sorts of scenario’s:
- verify the state of the network configuration during CI and prior to any actual deployment
- feeding the data models to other (micro-)services to enhance their insights into the network, e.g.:
- have the monitoring system better understand what constructs exist and should be monitored (BGP sessions for instance)
- feed the models into a service that exposes the models for other applications to consume
- making assertions against different snapshots for pre- and post-change validations
Creating a snapshot and asking some questions:
Let create a snapshot and have a look at the data models. First, we start the container with the batfish service:
docker pull batfish/allinone docker run --name batfish -v batfish-data:/data -p 8888:8888 -p 9997:9997 -p 9996:9996 batfish/allinone
We also install the relevant Python dependencies (using pipenv in this example):
git clone https://github.com/saidvandeklundert/batfish.git cd batfish python -m pipenv check python -m pipenv update python -m pipenv shell
From the same directory, we start an ipython session and then run the following:
from pybatfish.client.session import Session
from pybatfish.datamodel import *
from pybatfish.datamodel.answer import *
from pybatfish.datamodel.flow import *
SNAPSHOT_DIR = "snapshots/"
SNAP_SHOT_NAME = "example_snap_new"
SNAP_SHOT_NETWORK_NAME = "example_dc"
bf = Session(host="localhost")
bf.set_network(SNAP_SHOT_NETWORK_NAME)
bf.init_snapshot(SNAPSHOT_DIR, name=SNAP_SHOT_NAME, overwrite=True)
bf.set_snapshot(SNAP_SHOT_NAME)
The bf variable is a pybatfish client session that is used for all further interactions with the service.
The first thing of interest is the initIssues question that Batfish offers. This ‘out of the box’ question can detect several configuration issues for you. The second thing worth noting is the undefinedReferences, which can tell you if one of your configuration constructs (like a route-map) references something that does not exist (an access-list for instance).
bf.q.initIssues().answer().frame()
bf.q.undefinedReferences().answer().frame()
We can also look at Batfish questions to understand what the other options are. For example, here is how we can retrieve the DataFrame for interfaces:
bf.q.interfaceProperties().answer().frame()
Calling .frame() on any of the answers that Batfish provides us with transforms the answer table into a Pandas DataFrame.
Pandas
Many blogs and books have been written about Pandas and there is a lot to learn and discover about the framework. However, in the context of Batfish, there is a lot you can get done knowing just some of the basics. First, I’ll discuss the most important data structure in Pandas and after that, I will share some recipes that I turned to most often.
The data structure that is used to deliver all the goodness that Batfish has to offer is the Pandas DataFrame.
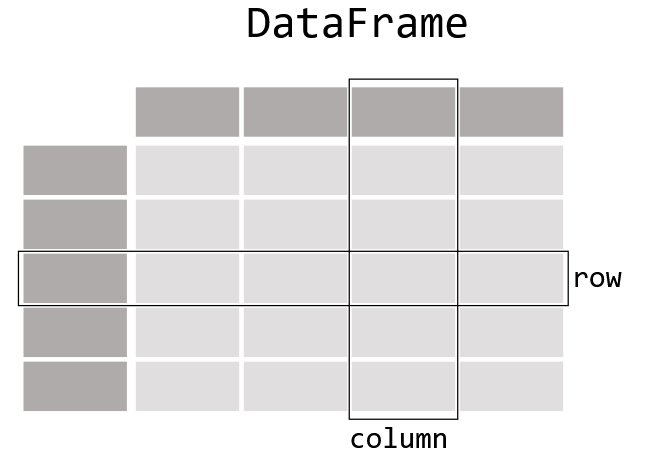
DataFrame: 2-dimensional data structure that can store different types of data. The DataFrame consists of columns and rows. Every column in a DataFrame is a Series.
Series: a one-dimensional labeled array capable of holding any data type. The axis labels are referred to as the index. The Series represent a single column in a DataFrame.
Basic Pandas operations
The best way to get started with Pandas is by using the basic operations in REPL. Start ipython and grab a DataFrame using one of the Batfish questions, for instance df = bf.q.interfaceProperties().answer().frame() to work with interface data. After this, explore the dataset with the following:
df.columns # check column names
df.iloc[0] # integer-location based indexing for selection by position
df.iloc[0:3] # slice of a DataFrame
df.head(6) # first 6 rows of the frame
df.tail(6) # last 6 rows of the frame
# select 1 row / Series (returns a Series)
df["Node"]
# select multiple rows / Series (returns a DataFrame)
df[["Interface","Incoming_Filter_Name",]]
# slice of a DataFrame, selecting columns 1 and 2
df.iloc[0:3,[1,2]]
# slice of the DataFrame selecting columns by name
df.loc[0:10,["Interface","Active"]]
# store data as CSV
df.to_csv("data.csv")
# read DataFrame from CSV
from_csv = pd.read_csv("data.csv")
Note about iloc and loc: with iloc, the row and the columns are selected using an integer to specify the index number of the row/column. With loc, you supply the label of the row/column name. In case the rows are labeled with integers, as is the case with Batfish models, you can select the rows using integers and the columns using their name. Generally, when working with Pybatfish, this is an easier approach.
Filtering and selecting values of interest
To use the data Batfish has on offer effectively, you need to be able to filter it to find the things that are relevant to your network. Pandas has put a lot of developer ergonomics in place to sift through and filter data. All of these examples were run against the DataFrame obtained using df = bf.q.interfaceProperties().answer().frame().
# display rows where the MTU is 1500:
df[df["MTU"] == 1500]
# put the selection criteria in a separate variable and then apply it to the DF:
mtu_1500 = df["MTU"] == 1500
df[mtu_1500]
# find interfaces that do NOT have an MTU of 1500:
df[~mtu_1500]
df[~mtu_1500][["Interface","MTU"]]
# alternative approach to finding interfaces that do NOT have an MTU of 1500:
small_mtu = df["MTU"] < 1500
big_mtu = df["MTU"] > 1500
df[small_mtu | big_mtu]
# find interfaces with UNUSED in the description:
# 'na=False' set cells that do not contain "UNUSED" to False
unused = df["Description"].str.contains("UNUSED", na=False)
df[unused]
# we can also do a case-insensitive search:
df["Description"].str.contains("UnUsEd", case=False, na=False)
# search for multiple values:
df["Description"].str.contains("UnUsEd|core", case=False, na=False)
# or apply a regex:
df["Description"].str.contains("U[a-z]u.*d", case=False, na=False, regex=True)
# find admin up interfaces:
admin_up = df["Admin_Up"] == True
df[admin_up]
# find admin up AND unused:
df[unused & admin_up]
In case a cell contains something like a string or an integer, applying a comparison operator to it is relatively straightforward. Filtering on cells that contain a composite type can be a bit trickier. The follow explains what I mean by this:
type(df["Description"].iloc[0])
>>> str
type(df["Interface"].iloc[0])
>>> pybatfish.datamodel.primitives.Interface
vars(df["Interface"].iloc[0])
>>> {'hostname': 'as1border1', 'interface': 'Ethernet0/0'}
The “Description” column is a string. You can easily make any comparisons there. The “Interface” column is a bit different though. Filtering rows for conditions applied to the hostname of interface field can be done using a Lambda:
df[
df.apply(
lambda row: "core" in row["Interface"].hostname,
axis=1, # this applies the function to each row, use 0 to select column
)
]
We are free to add additional logic to the Lambda and add criteria to filter based on other columns as well, so the Lambda is also a good choice in case you want to use a complex expression for filtering:
df[
df.apply(
lambda row: "core" in row["Interface"].hostname
and row["MTU"] != 1500,
axis=1,
)
]
df[
df.apply(
lambda row: "core" in row["Interface"].hostname
and row["MTU"] != 1500
and row["Active"],
axis=1,
)
]
Lastly, for certain scenario’s, knowing you can iterate the DataFrame might also come in handy:
for idx, row in df.iterrows():
print(idx)
print(row["Interface"])
print(row["MTU"])
Pytest
Pytest according to pytest:
The pytest framework makes it easy to write small, readable tests, and can scale to support complex functional testing for applications and libraries.
Working with Pytest is a joy to me due to the simplicity of the framework and the fact that there are a lot of features in pytest that can make your life easy. There is a fantastic book on the framework which I can really recommend as it will guide you through the most usefull and important features of the framework:

In the context of using Batfish to test the network, I am going to keep it simple and straightforward. I will mainly let pytest drive the execution of the tests making use of a small number of features pytest has on offer.
First, I will show you how to run the tests, then I will discuss fixtures and after that, I will cover some example tests.
Running the tests
The repo that comes with this article has a directory where all the tests are located. Additionally, there is a pytest.ini file containing the pytest configuration. To run all the tests, simply run pytest or python -m pytest from the top-level directory of the repository.
Pytest will then:
- read the configuration options
- look for tests in the test directory
- identify all test functions (functions prefixed with
test_in their name) - execute all the tests
- report the results of the tests
Fixtures
Pytest fixtures can be used to initialize resources that tests functions can use. In our case, (most) test functions will require a pybatfish session and a snapshot. Having every test function setup a pybatfish session with the Batfish service and run a snapshot would not make sense. Additionally, having the Batfish service return the same Pandas DataFrame over and over again for different unit tests is also wastefull.
What we start off doing is write a function that returns a pybatfish Session during which we already created a snapshot. We put the fixture in a file called conftest.py. This way, pytest automatically picks up the fixture. Second, we decorate the function we want to serve as fixture with the pytest fixture decorator and specify that the fixture is to be used throughout the testing session. This way, it is set up only once and we can re-use it hundreds of times:
import pytest
import pybatfish
from pybatfish.client.session import Session
from pybatfish.datamodel import *
from pybatfish.datamodel.answer import *
from pybatfish.datamodel.flow import *
SNAPSHOT_DIR = "snapshots/"
SNAP_SHOT_NAME = "example_snap_new"
SNAP_SHOT_NETWORK_NAME = "example_dc"
@pytest.fixture(scope="session")
def bf() -> pybatfish.client.session.Session:
"""returns a BatFish session for reuse throughtout the tests."""
bf = Session(host="localhost")
bf.set_network(SNAP_SHOT_NETWORK_NAME)
bf.init_snapshot(SNAPSHOT_DIR, name=SNAP_SHOT_NAME, overwrite=True)
bf.set_snapshot(SNAP_SHOT_NAME)
return bf
Using the fixture is done by passing it as argument to a test function:
def test_something(bf):
assert ...
Pytest collects all fixtures as soon as you run tests and you can, having created the fixture in conftest.py, reference it anywhere in your tests.
Another thing that is nice to know is the fact that fixtures can also be used by other fixtures. Since we will be writing many tests for interface properties as well as BGP sessions, we can use the previous fixtures to create new ones that return interface and BGP data.
@pytest.fixture(scope="session")
def bgp_peer_configuration(bf) -> pd.DataFrame:
df = bf.q.bgpPeerConfiguration().answer().frame()
return df
@pytest.fixture(scope="session")
def interface_properties(bf) -> pd.DataFrame:
df = bf.q.interfaceProperties().answer().frame()
return df
This will make the tests run considerably faster when compared to having every tests setup a session and get the DataFrame out of the service. And creating fixtures for resources that you use repeatedly not only speeds things up considerably, they also reduces the amount of clutter in your tests.
Examples tests
Here are some sample tests that should give you a basic idea on how to go about creating tests that are relevant to your own network.
Testing for issues and unreferenced configuration snippets.
The initIssues question produces a DataFrame with an issue per row. Testing for this can be done like so:
def test_issues(bf):
"""
Test for the absence of issues detected by
the checks that ship with Batfish.
"""
df = bf.q.initIssues().answer().frame()
assert df.empty is True
We pass in the fixture bf and then extract the desired DataFrame. We know that there are no issues in case the DataFrame is empty, so for that reason we use assert df.empty is True.
Next, we use the undefinedReferences questions:
def test_undefined(bf):
"""
Test for the existence of references to undefined
configuration constructs. For instance,
references to non-existent route-maps.
"""
df = bf.q.undefinedReferences().answer().frame()
assert df.empty is True
Testing BGP configuration aspects
Many networks have been brought down by BGP mishaps. Batfish understands the BGP configuration and can deduce from the configuration whether or not it should be possible for 2 peers to reach the Established state:
def test_ibgp_session_status(bf):
"""
Verify iBGP sessions can reach the ESTABLISHED state.
"""
df = bf.q.bgpSessionStatus().answer().frame()
same_as = df["Remote_AS"].astype(int) == df["Local_AS"]
node_status = df[same_as][["Node", "Established_Status"]]
not_established = node_status[node_status["Established_Status"] != "ESTABLISHED"]
assert not_established.empty
The data available in the BGP related DataFrames pretty substantial. For instance, we can also filter all BGP sessions to only include eBGP sessions and then make the assertion that we have at least 1 import policy applied:
def test_external_peers_no_empty_import_policies(bgp_peer_configuration):
"""
Check if there are eBGP sessions have no import policy applied.
"""
diff_as = bgp_peer_configuration["Local_AS"] != bgp_peer_configuration[
"Remote_AS"
].astype(int)
no_import_policy = different_as[different_as["Import_Policy"].str.len() == 0]
potential_offenders = no_import_policy[["Node", "Remote_IP"]]
assert (
no_import_policy.empty
), f"eBGP sessions without import policy:\n{potential_offenders}"
Another thing we could test for is ensuring that we have a specific filter applied to all eBGP neighbors:
def test_external_peers_have_specific_import_policy_applied(different_as):
"""
Verify all eBGP sessions have 'internet-edge' applied on import.
"""
nodes_without_import_policy = different_as[
different_as.apply(
lambda row: "internet-edge" not in list(row["Import_Policy"]),
axis=1,
)
]
assert (
nodes_without_import_policy.empty
), f"eBGP with missing import policy 'internet-edge':\n{nodes_without_import_policy}"
Testing interface configuration aspects:
The interfaces DataFrames has a lot of datapoints that you can write assertions for. Just to mention a few here, we can assert that every interface has an MTU of 1500 at minimum:
def test_minimum_mtu(interface_properties):
"""Verify all nodes have an MTU of at least 1500"""
small_mtu = interface_properties["MTU"] < 1500
assert len(
interface_properties[small_mtu]
), f"There are interfaces with an MTU below 1500: {interface_properties[small_mtu]}"
Or perhaps that is not enough, perhaps we want to verify that every node has the exact same MTU configured:
def test_for_deviating_mtu(interface_properties):
"""Verify nodes do not have a deviating MTU"""
mtu_std = interface_properties["MTU"] == 1500
interfaces_with_deviating_mtu = interface_properties[~mtu_std][["Interface", "MTU"]]
assert (
interfaces_with_deviating_mtu.empty
), f"deviating interfaces:{interfaces_with_deviating_mtu}"
If we have a layered network, we can also check for MTU sizes based on the node to which the interface is attached. One way of doing so could be as follows:
def test_minimum_mtu_core_routers(interface_properties):
"""Verify that nodes with 'core' in the hostnames are
deployed with a minimum MTU of 9000."""
for _, row in interface_properties.iterrows():
if "core" in row["Interface"].hostname:
assert row["MTU"] > 9000
One last interface example could be verifying that interfaces with a certain description are not administratively enabled:
def test_unused_are_shut(interface_properties):
"""
Verify all interfaces with the 'UNUSED' description
are administratively shut.
"""
unused = interface_properties["Description"].str.contains("UNUSED", na=False)
admin_up = interface_properties["Admin_Up"] == True
unused_and_up = interface_properties[unused & admin_up]
assert unused_and_up.empty
Testing filter configuration aspects:
Misconfigured firewall filters can wreak havoc on a network. Batfish translates vendor specific terminology to a common one and allows you to make assertions on how filters affect certain traffic flows. Possibilities are endless here, but this might serve as a nice starting point:
def test_should_be_allowed(bf):
"""
Asserts we can ssh into 2.1.1.1/28 while sourcing traffic from 192.168.1.0/24.
Will execute the test on every node where the 'MGMT_EXAMPLE' is present.
"""
ssh_flow = HeaderConstraints(
srcIps="192.168.1.0/24", dstIps="2.1.1.1/28", applications=["ssh"]
)
df = bf.q.testFilters(headers=ssh_flow, filters="MGMT_EXAMPLE").answer().frame()
assert all(action == "PERMIT" for action in df["Action"].values), df[
df["Action"] != "PERMIT"
][["Node", "Action"]]
First up, we specified the flow using the HeaderConstraints. In this case, SSH traffic from a specific source to a specific destination network.
Then, we run bf.q.testFilters and pas it the flow and reference the name of the filter against which we want to test the flow. The DataFrame returned by bf.q.testFilters will inform us on whether or not the flow is permitted or denied under the “Action” column. So, we test to see that none of the nodes that report a “DENY” for this flow and filter combination.
Note that in addition to being able to work with stateless access-lists, Batfish also has the capabilities to working with stateful firewall rules for a variety of firewalls.
Things that Batfish does not do (yet)
For a number of reasons, Batfish is not going to be able to capture everything. First of all, you could be using a vendor that is not supported by Batfish. But apart from that, there are going to be parts of the configuration that Batfish does not understand. Some notable examples that caught my eye:
- MPLS
- IPv6
- QoS configuration constructs
This is not an exhaustive list. The best way to see how well your network configurations are supported by Batfish is simply going to be by trying it out. Clone this repo, follow the quickstart and replace the configurations in the snapshot directory with your own.
Conclusion
After playing with Batfish for some time I can say that the tool really lived up to my expectations. It is relatively easy to setup and get started with and once you understand how to work with the Batfish service, writing unit tests that are specific to your network is easy and fun. The data models on offer by Batfish cover a lot of configuration constructs that have proven to cause major outages. Things like BGP session configuration aspects, firewall filters, interface settings and much more. In this blog, I stuck to the more basic assertions and test that can be run using Batfish. Batfish has more on offer though, like doing a traceroute through a topology for example.
To understand more of the capabilities that Batfish has on offer, you can have a look at the following: